Important
This repository is an experimental SM70/SM75 fork of QwenLM/FlashQLA.
It is not an official FlashQLA release and does not replace the upstream Hopper/SM90 implementation.
FlashQLA-SM70-SM75
Experimental forward-inference support for Qwen-style Gated DeltaNet on SM70/SM75-class NVIDIA GPUs.
This fork keeps the upstream Hopper/SM90 TileLang path intact and adds an explicit legacy backend entry point for Volta/Turing inference devices. The current runtime validation target is RTX 2080 Ti / SM75. SM70 currently has compile coverage, but V100-class runtime validation is still required before making performance claims.
Changes in This Fork
- Adds
flash_qla.ops.gated_delta_rule.legacy.chunk_gated_delta_rule_fwd_legacy. - Adds a lazy-built CUDA extension for a forward-only SM70/SM75-class Gated DeltaNet backend.
- Keeps the upstream Hopper/SM90 TileLang path unchanged.
- Keeps the legacy path explicit instead of silently replacing the upstream high-level API.
- Adds CUDA correctness tests for the supported legacy path.
- Documents the supported scope, validation status, and benchmark caveats separately from upstream Hopper results.
Supported Scope
Supported:
- forward inference only
- SM70/SM75-class CUDA devices as the intended legacy target family
- scalar-gate Gated DeltaNet
- Qwen-style grouped-query head mapping
- primary optimized shape:
D=128 - explicit legacy API entry point
Not supported:
- backward kernels or training
- automatic dispatch from the upstream high-level API
- generic support for all pre-Hopper NVIDIA GPUs
- runtime performance claims for SM70 before V100-class validation
- SM80/SM86/SM89 support claims
- automatic default dispatch for non-Hopper devices
Current Validation
Runtime validation was performed on RTX 2080 Ti / SM75.
Standalone kernel timing for a Qwen-like shape:
B=1, T=512, Hq=16, Hv=32, D=128- control recurrent path: about
1.126 ms - optimized legacy path on SM75: about
0.520-0.533 ms - GDN-stage speedup: about
2.1x
GGUF runtime profiling on SM75:
- default fused GDN:
406.656 ms - legacy fast path:
195.105 ms - GDN-stage speedup: about
2.08x
Whole-request impact under the same server parameters:
- prefill:
+7.17% - decode:
+0.61% - wall time:
-3.49%
SM70 status:
- compile check passes
- runtime validation is pending
- V100-class benchmarking is needed before claiming SM70 performance
Fork wrapper status:
- Python syntax check passes
- CUDA tests are included under
tests/test_legacy_sm_gdn.py - CUDA PyTorch runtime validation still requires a CUDA-enabled PyTorch environment
Positioning
This fork is meant to make the SM70/SM75 experiment reproducible and reviewable. It should be treated as an upstreamable experimental branch, not as a separate long-term replacement for FlashQLA.
The original upstream README follows below.

| 📜 Blog |
Introduction
FlashQLA is a high-performance linear attention kernel library built on TileLang. FlashQLA applies reasonable operator fusion and performance optimization to the forward and backward passes of GDN Chunked Prefill, achieving 2-3× forward speedup and 2× backward speedup over the FLA Triton kernel across multiple scenarios on NVIDIA Hopper. The efficiency gains are particularly pronounced in pretraining scenarios and edge-side agentic inference.
Key features:
1.Gate-driven automatic intra-card context parallelism. By exploiting the exponential decay property of the GDN gate, FlashQLA automatically enables intra-card CP under TP, long-sequence, and small-head-count settings, improving GPU SM utilization.
2.Hardware-friendly algebraic reformulation. We reformulate the forward and backward flows of GDN Chunked Prefill to a certain extent, effectively reducing Tensor Core, CUDA Core, and SFU overhead without sacrificing numerical precision.
3.TileLang fused warp-specialized kernels. Rather than following the step-by-step decomposition into independent kernels, nor fusing the entire computation flow into a single kernel, we take CP and backward requirements into account, use TileLang to build several key fused kernels, and manually implement warpgroup specialization to overlap data movement, Tensor Core computation, and CUDA Core computation.
Requirements
- SM90 or above
- CUDA 12.8 or above
- PyTorch 2.8 or above
Installation
git clone https://github.com/QwenLM/FlashQLA.git
cd FlashQLA
pip install -v .
Usage
High-level API
import torch
from flash_qla import chunk_gated_delta_rule
o, final_state = chunk_gated_delta_rule(
q=q, # [B, T, H_q, K]
k=k, # [B, T, H_q, K]
v=v, # [B, T, H_v, V]
g=g, # [B, T, H_v]
beta=beta, # [B, T, H_v]
scale=scale,
initial_state=initial_state, # optional, [B, H_v, K, V]
output_final_state=True,
cu_seqlens=cu_seqlens, # optional, for variable-length sequences
)
Low-level API
For separate forward and backward calls:
from flash_qla import chunk_gated_delta_rule_fwd, chunk_gated_delta_rule_bwd
# Forward
g, A, o, h, final_state = chunk_gated_delta_rule_fwd(
q, k, v, g, beta, scale=scale, initial_state=h0, cu_seqlens=cu_seqlens
)
# Backward
dq, dk, dv, db, dg, dh0 = chunk_gated_delta_rule_bwd(
q, k, v, g, beta, A, do, dht=dht, scale=scale, initial_state=h0, cu_seqlens=cu_seqlens
)
Tests
# require flash linear attention for comparison
pip install flash_linear_attention==0.5.0
cd tests
python test_gdr.py --set develop
python test_gdr.py --set varlen --num-heads 32
python test_gdr.py --set profile --num-heads 32
python test_gdr.py --set product --ref-dtype float32 --num-heads 32
Benchmark
We benchmarked FlashQLA against the FLA Triton and FlashInfer baseline (FLA 0.5.0, Triton 3.5.1, FlashInfer 0.6.9, TileLang 0.1.8) on the head configurations used by the Qwen3.5 / Qwen3.6 family h_k,v \in {64, 48, 32, 24, 16, 8}, corresponding to TP1 through TP8.
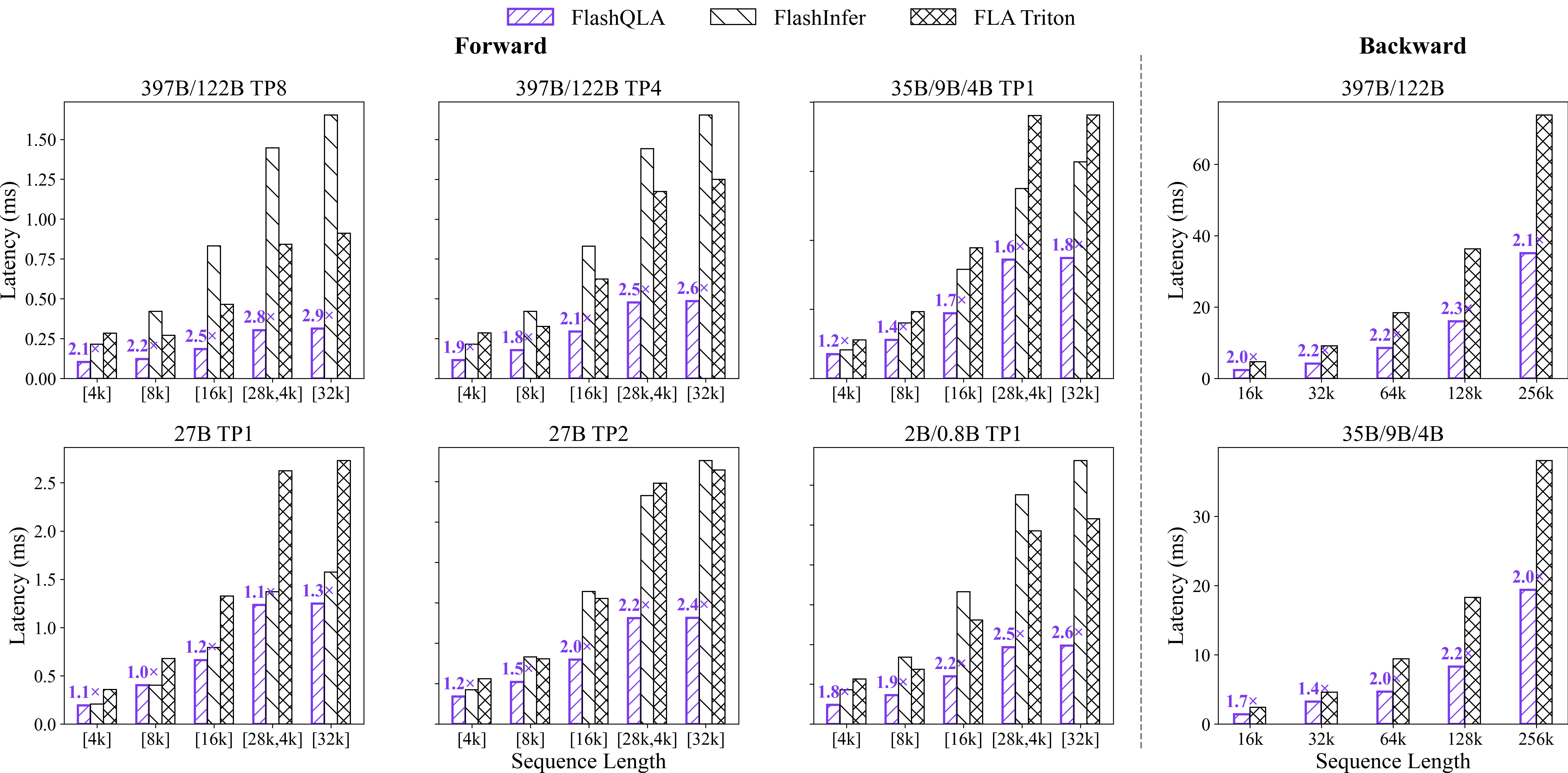
Specifically, the forward (FWD) benchmarks measure single-kernel latency for different models and TP settings under varying batch lengths, while the backward (BWD) benchmarks examine the relationship between total token count within a batch and latency during a single update step.
More detail in benchmark_results_H200.txt.
# require flash linear attention and flashinfer for comparison
pip install flash_linear_attention==0.5.0 flashinfer-python==0.6.9
cd benchmark
python bench_gated_delta_rule.py
Acknowledge
FlashQLA is inspired by Flash Linear Attention, TileLang and FlashInfer projects.
License
FlashQLA is released under the MIT License.
Citation
@misc{flashqla2025,
title={FlashQLA: Flash Qwen Linear Attention},
author={Zhang, Chengruidong and Lin, Xi and Jiang, Huiqiang and Wang, Zekun and Li, Xiao and Cao, Yizhong and Zhuang, Bohan and Men, Rui and Zhang, Jianwei and Zheng, Bo and Lin, Junyang and Liu, Dayiheng and Zhou, Jingren},
year={2026},
publisher={GitHub},
howpublished={\url{https://github.com/QwenLM/FlashQLA}},
}